
AI answers are quickly becoming a “first impression” layer for your brand. Prospects ask ChatGPT for vendor shortlists, Gemini for quick explanations in their Google workflow, Claude to summarize long documents, and Perplexity when they want sources right away. That makes an AI comparison more than a features debate, it is a visibility and revenue question: which engines mention you, how they describe you, and whether they cite you at all.
This guide compares ChatGPT vs Gemini vs Claude vs Perplexity through the lens of real marketing and SEO work, especially AI search visibility (GEO/AEO). You will learn where each tool tends to perform best, what “good” looks like for brand mentions, and how to build an engine-by-engine monitoring routine.
How to evaluate an AI engine (for marketing and AI visibility)
Most comparisons focus on “which model is smarter.” For go-to-market teams, the practical differences are usually:
1) Source behavior and citations
If you care about AI search presence, you should care about:
- Does the engine cite sources by default, sometimes, or rarely?
- Are citations stable across repeats of the same prompt?
- Does it pull from the open web, curated partners, or both?
Perplexity is widely known for making citations central to the experience. Others may cite, but the style and consistency can vary.
2) Freshness and web access (when enabled)
For industries where the “right answer” changes weekly (pricing, availability, policy updates, local inventory, events), engines that can use current web sources are often more useful. The catch is that browsing and freshness can depend on plan, region, and product mode.
3) Task fit: writing, reasoning, summarization, research
Marketers use these tools for different jobs:
- Drafting and rewriting landing pages, ads, and emails
- Summarizing research, briefs, and internal documents
- Competitive research and positioning
- Content ideation and SEO structuring
- Customer support macros and FAQs
4) Governance for teams
For agencies and brands, governance matters as much as quality:
- Admin controls and auditability
- Data handling and privacy expectations
- Workspace collaboration
- Tool integrations (docs, spreadsheets, CMS)
You should validate governance needs with each vendor’s current documentation (for example: OpenAI, Google Gemini, Anthropic Claude, Perplexity).
ChatGPT vs Gemini vs Claude vs Perplexity: quick comparison
The simplest way to read this AI comparison is: ChatGPT is often a general-purpose workhorse, Gemini is tightly aligned to Google workflows, Claude is strong for long-form analysis and careful writing, and Perplexity is optimized for sourced research and “answer-first” discovery.
Here is a practical snapshot for marketers.
| Engine | Best at (common marketing use) | Typical strengths | Typical watch-outs for AI visibility work |
|---|---|---|---|
| ChatGPT | Ideation, drafting, structured outputs, internal workflows | Fast iteration, strong general coverage, good for prompt-based content operations | Brand mentions can vary by phrasing, sourcing and citation style can be inconsistent depending on mode |
| Gemini | Quick answers, multimodal tasks, teams living in Google | Convenience inside Google ecosystem, strong for day-to-day knowledge work | If your visibility relies on citations, you may need to test how often it cites and what it pulls from |
| Claude | Long documents, nuanced writing, policy-sensitive or careful tone | Strong summarization and “read a lot, then synthesize” workflows | Not designed as a citation-first search engine, so measuring “credit” can be harder |
| Perplexity | Research with citations, comparison shopping, “what’s the source?” questions | Source-forward UX, fast research loops, often easier to audit why an answer happened | Can over-index on sources it trusts, if you are not in those sources you may not appear |
Deeper breakdown by engine
The goal here is not to crown a winner. It is to help you choose the right engines to monitor, and the right remediation when your brand is missing.
ChatGPT: broad utility, strong for workflows
ChatGPT is frequently used as a general assistant across writing, brainstorming, data shaping, and internal enablement. For marketing teams, that means it often influences:
- Vendor shortlists (“best X tools for Y”) even before a prospect visits Google
- Draft copy and positioning that gets reused across docs and decks
- First-pass explanations of your category to buyers and internal stakeholders
Visibility implication: If your brand is not mentioned for your key category prompts, you can lose mindshare even if your traditional SEO is strong. Your monitoring should focus on “recommendation prompts” and “comparison prompts,” not only factual queries.
Gemini: integrated convenience for Google-centric teams
Gemini is a natural default for organizations that live in Google products. That matters because convenience drives usage, and usage drives which assistant shapes understanding of your category.
Visibility implication: Gemini exposure can be closely tied to how your brand appears across authoritative web sources and well-structured site data. If your brand has inconsistent entity signals (name variants, outdated descriptions, weak structured data), you can get partial or incorrect mentions.
Claude: excellent for long-context analysis and careful writing
Claude is often chosen for tasks where users paste in long reports, meeting transcripts, product docs, policy text, or multi-page research and ask for synthesis.
Visibility implication: Claude is less “search-native” in the way Perplexity is, so brand discovery may happen through:
- Users asking it to compare known options
- Users pasting content that already includes (or omits) your brand
That makes your thought leadership distribution (PDFs, guides, partner docs, industry roundups) especially relevant, because those are the artifacts users may feed into the tool.
Perplexity: research-first, citation-forward discovery
Perplexity is widely used as a research layer, especially for “what are the best options and why?” questions. Because sources are part of the experience, it is often easier to debug:
- Which domains are being cited
- Whether you appear as a cited source
- Whether you are mentioned but not credited
Visibility implication: If Perplexity does not cite your site (or cites competitors), you need to treat that as a distribution and authority problem, not just an on-page SEO problem. You may need better third-party coverage, clearer entity information, and AI-ready pages that are easy to quote.
What this means for brands: AI visibility is not one channel
Many teams still treat “AI search” like one platform. In practice, each engine has its own:
- Prompt patterns (how people ask)
- Output norms (how it structures recommendations)
- Source preferences (what it trusts and cites)
So the right question is not “Which AI is best?” It is:
- Where are my customers asking? (B2B buyers often use ChatGPT for evaluation, researchers lean Perplexity, Google-native teams use Gemini.)
- Which prompts drive revenue? (Category comparisons, “best for” queries, local availability, integrations, pricing expectations.)
- Do I show up with the right positioning? (Not just presence, but message accuracy.)
A practical testing plan (you can run this in 60 minutes)
If you are not actively testing prompts, you are guessing. Here is a lightweight routine that works across ChatGPT, Gemini, Claude, and Perplexity.
Step 1: build a prompt set that matches buying intent
Create 20 to 40 prompts in four buckets:
- Category discovery: “What is [category] and what should I look for?”
- Shortlist creation: “Best [category] for [use case / industry / budget]”
- Direct comparison: “Compare [Brand A] vs [Brand B] vs [Your Brand]”
- Objection handling: “Is [category] worth it for [company size], what are the risks?”
Keep wording consistent so you can see which engines are stable versus sensitive to phrasing.
Step 2: record four visibility metrics
Track outputs like you would track rankings. The most useful “AI visibility” metrics are:
- Presence rate: In how many prompts does your brand appear?
- Recommendation rate: In how many prompts are you recommended (not merely listed)?
- Message accuracy: Are category, features, geography, and differentiators correct?
- Citation and credit rate: When sources are shown, are you cited, and are you cited correctly?
Step 3: map “why you lost” for each missing mention
When you do not show up, the cause is usually one of these:
- Weak or inconsistent entity signals (name, category, location, parent company)
- Thin or generic product pages that are hard to quote
- Missing FAQ content for common comparisons and objections
- Competitors have stronger third-party coverage (reviews, lists, directories)
- Your site metadata does not clearly communicate what you are, who you serve, and where you operate
Step 4: fix the highest-leverage surfaces first
Prioritize pages and entities most likely to be used in answers:
- Homepage and “About” (clear entity definition)
- Core product or service pages (scannable, specific, quotable)
- Location pages (for multi-location brands)
- Comparison pages and “alternatives” pages (if appropriate)
- FAQ hubs that match your prompt set
Optimization tactics that help across all four engines
You do not need “four SEO strategies.” You need one strong foundation that is easy for models to interpret and retrieve.
Make your entity unambiguous
Ensure consistency across:
- Brand name variants (CapstonAI vs Capston AI, abbreviations)
- Category labels (what you are, in plain language)
- Geographic relevance (where you operate)
- Ownership and official domain (avoid duplicate domains confusing attribution)
Publish AI-ready FAQs (not fluffy blog FAQs)
High-performing FAQ content is:
- Specific to real buyer questions
- Written with direct answers in the first sentence
- Supported by details that reduce ambiguity (numbers, constraints, definitions)
Tighten metadata and structured data
Strong metadata helps both classic search and AI retrieval. At minimum:
- Clear titles and descriptions that match intent
- Clean canonicalization and indexation
- Relevant schema where appropriate (Organization, Product, FAQPage, LocalBusiness)
If you already do this for SEO, you are partway to GEO. The key difference is that AI engines reward extractable, well-scoped answers.
Build “citation gravity” with credible third-party mentions
AI engines often reflect the broader web’s consensus. If competitors appear more, it is frequently because they are discussed more in:
- Industry roundups
- Partner directories
- Review sites
- Case studies and press
Your plan should include PR and partnerships, not only on-site optimization.
Common pitfalls in AI comparisons (and how to avoid them)
Pitfall 1: choosing one engine and ignoring the rest
Your buyers do not standardize on one assistant. Agencies especially need multi-engine coverage because clients’ audiences vary.
Pitfall 2: measuring “traffic” only
AI answers can reduce clicks while still driving brand selection. You need visibility metrics like presence, recommendation rate, and citation share, then connect them to pipeline and revenue.
Pitfall 3: optimizing content without monitoring prompts
Without prompt tracking, you cannot tell whether fixes improved visibility or if the engine simply varied the output.
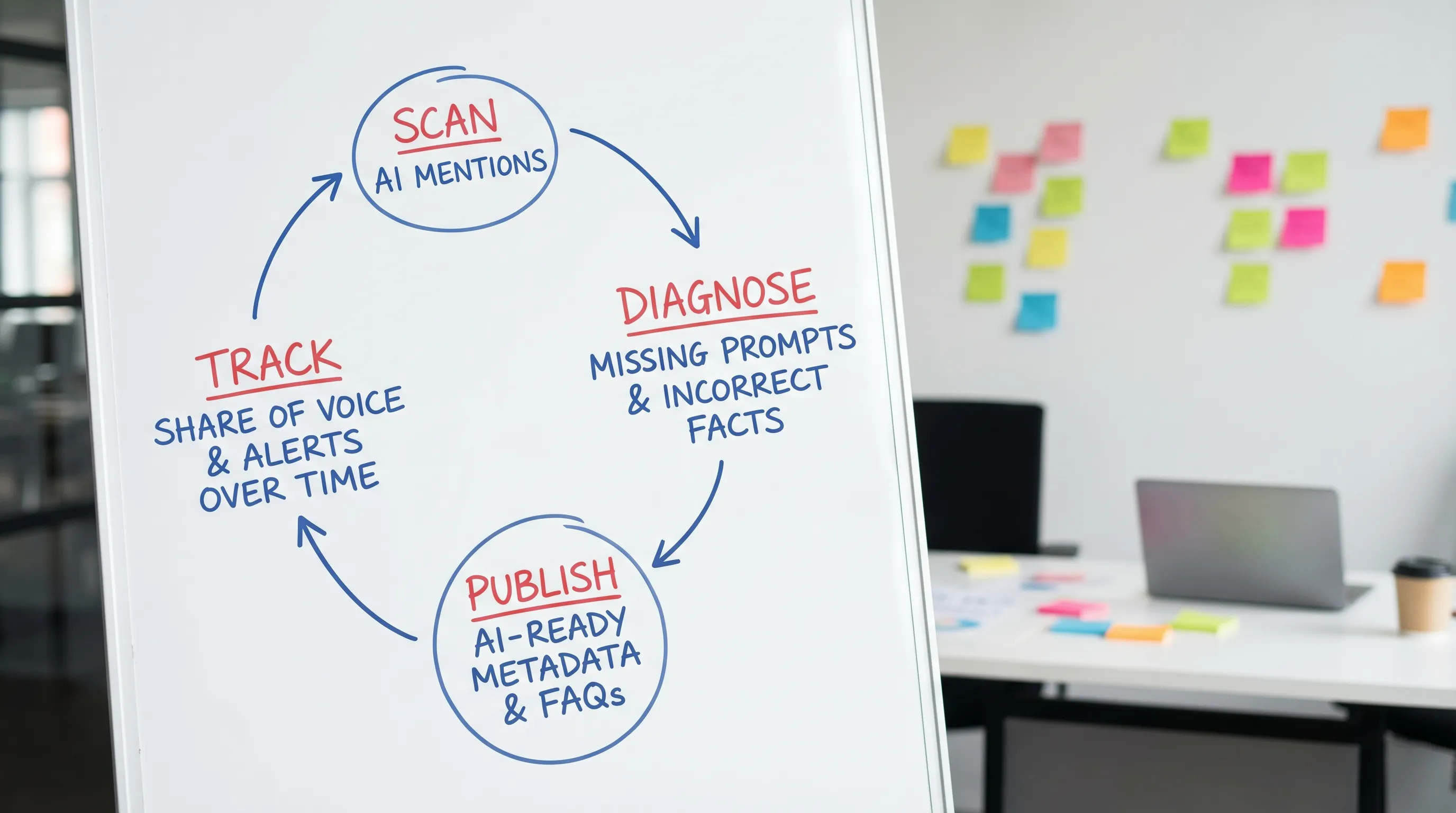
Frequently Asked Questions
Which is better for research, ChatGPT or Perplexity? Perplexity is often preferred for research workflows where citations matter, because sources are central to the experience. ChatGPT is often stronger for drafting, structuring, and iterating on outputs, depending on mode and settings.
Which AI is best for marketers in 2026? It depends on your workflow. Many teams use a mix: one assistant for writing and ideation, another for source-backed research, and all of them for monitoring brand mentions across prompts.
Do these AI tools pull from the same sources as Google search? Sometimes there is overlap, but they are not identical. Each system has different retrieval methods, partnerships, and interface choices around citations and web access, so visibility can differ even for the same query.
How do I know if my brand is visible in ChatGPT, Gemini, Claude, and Perplexity? Run a repeatable prompt set (category, shortlist, comparisons, objections), then measure presence rate, recommendation rate, message accuracy, and citations. Do this monthly, and after major site changes.
What should I fix first if an AI engine describes my brand incorrectly? Start with your core entity pages (homepage, about, product pages, location pages) and make your positioning explicit in the first 1 to 2 sections. Then reinforce with schema, FAQs, and credible third-party mentions.
Turn this AI comparison into measurable visibility
Reading comparisons is useful, but tracking your actual mentions across ChatGPT, Gemini, Claude, and Perplexity is what turns AI search into a predictable channel.
CapstonAI helps brands and agencies measure and improve AI visibility with AI visibility scans, competitor and market tracking, prompt and mention mapping, automated content recommendations, AI-ready FAQ and metadata publishing, multi-location management, share of voice analytics, and critical alerts.
Get started with a free AI visibility audit at capston.ai.


