
Brand recommendations inside ChatGPT, Gemini, Claude, Perplexity, and Google’s AI answer surfaces often feel mysterious. One day your company is mentioned as a “top option,” the next day it disappears, even though your Google rankings did not change.
That is because an AI model does not “rank websites” the way classic search does. In most AI search experiences, the model generates an answer by combining (1) its learned knowledge, (2) retrieved sources (when the product is connected to search or browsing), and (3) safety and quality policies. Your brand gets recommended when it becomes a strong, low-risk match for the user’s intent and the system can justify that choice with credible evidence.
What “an AI model recommending brands” actually means
In practice, a brand recommendation is rarely the output of a single model. It is usually a pipeline:
- A language model interprets the user’s question.
- A retrieval layer may pull documents from the open web, licensed sources, or a curated index.
- A ranking and filtering layer prioritizes sources that appear trustworthy and relevant.
- The model generates a response that is consistent with both the retrieved evidence and policy constraints.
So when people ask, “How does the AI model choose which brands to recommend?”, the most useful answer is: it chooses brands that it can defend with evidence, that match the constraints in the prompt, and that are safe to recommend.
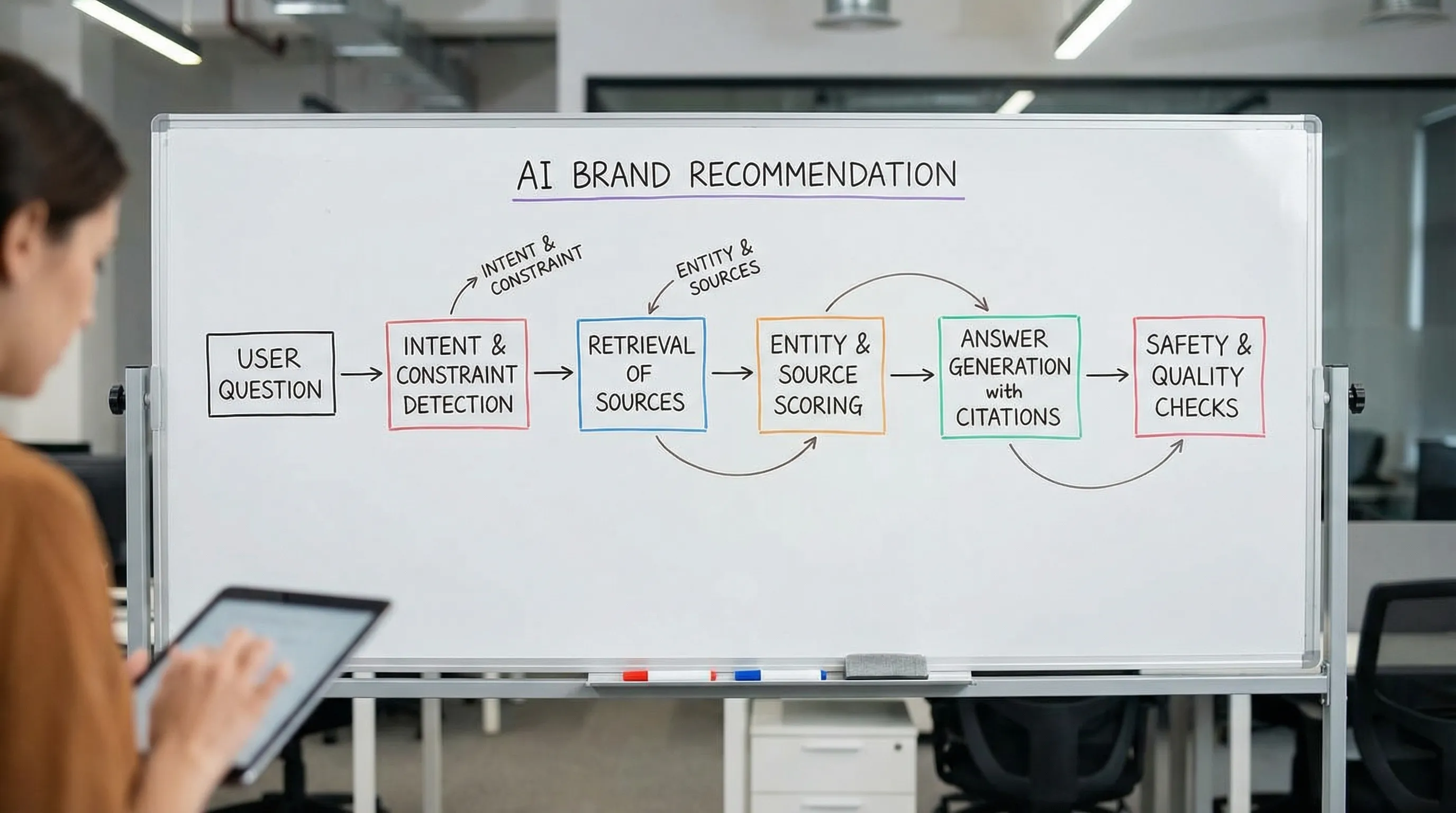
The recommendation pipeline (and where your brand can win or lose)
Different platforms implement this differently, but the mechanics are similar enough that you can optimize for them.
Intent and constraint detection
First, the system interprets what the user is really asking, often extracting constraints such as:
- Category and use case (for example, “best invoicing tool for freelancers”)
- Location or service area
- Budget and pricing model
- Size (SMB vs enterprise)
- Requirements (integrations, compliance, delivery time)
This step matters because AI answers tend to be constraint-first. If the prompt implies “for a small team, low budget, quick setup,” brands positioned as enterprise, high-cost, or complex may be filtered out even if they are well-known.
Candidate generation (what brands even get considered)
Next, the system forms a set of candidates. Candidates can come from:
- The model’s internal, trained knowledge (which can be incomplete or outdated)
- Retrieved documents (common in AI search experiences)
- Structured “entity” sources (knowledge graphs, business listings, product catalogs)
If your brand is not consistently described in places the system can access, it may never enter the candidate set. This is one reason “being mentioned” across the web can matter as much as “ranking”.
Evidence gathering via retrieval (when the system uses sources)
Modern AI answer systems often use some form of retrieval-augmented generation (RAG), a widely discussed approach in research and industry. A canonical reference is the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
In a RAG-style flow, the system retrieves passages that appear relevant, then uses those passages to produce the answer. This creates a practical rule:
Brands that are described clearly, repeatedly, and consistently in retrievable sources are easier to recommend.
If your key product facts, locations, policies, pricing approach, and category positioning are unclear or scattered, the model has less “support” to safely recommend you.
Entity resolution (are you the brand the model thinks you are?)
AI systems try to map text mentions to real-world entities. This is where many brands get hurt.
Common problems include:
- Name collisions (similar brand names in other countries or categories)
- Multiple domains, subdomains, and inconsistent canonicalization
- Franchise or multi-location brands with inconsistent location pages
- Mismatched details across the web (addresses, business names, phone numbers)
When entity resolution is uncertain, the safest behavior is often to avoid strong claims. That can translate into fewer brand recommendations.
Source and reputation weighting (trust is a filter, not a bonus)
Even when a brand is relevant, the system still needs to “trust” the evidence.
Across AI search products, signals of trust often look like:
- The source has a strong reputation for the topic (industry publications, standards bodies, respected reviewers)
- The information is consistent across multiple sources
- The content is explicit and extractable (clear claims, not vague marketing)
- The page is accessible and technically clean enough to be processed
This is conceptually aligned with the broader industry focus on demonstrating expertise and trustworthiness, which also appears in Google’s guidance on content quality.
Safety and policy constraints (why “best” prompts do not always produce “best” answers)
Most AI assistants are tuned with instruction-following and safety techniques (often discussed under RLHF style training). A widely cited reference on this family of methods is Training language models to follow instructions with human feedback (InstructGPT).
Policy constraints influence brand recommendations in ways marketers often miss:
- Highly regulated topics (health, finance, legal) may trigger cautious, non-committal answers.
- Claims that are hard to verify may be avoided.
- Some assistants prefer recommending categories or “what to look for” rather than specific brands.
The practical implication is that clarity and verifiability can outperform hype.
The main factors that make a brand recommendable
Think of “recommendability” as a composite score. You do not control the model, but you can control the signals it is most likely to rely on.
1) Fit to the user’s constraints
AI assistants tend to reward brands that map cleanly to a user’s scenario. You can support this by publishing pages that clearly answer:
- Who is this for?
- What problem does it solve?
- What does it integrate with?
- Where is it available (countries, cities, service areas)?
- What is the pricing model (even if you do not publish exact pricing)?
If that information is missing, the model may select a competitor simply because the competitor is easier to place into the prompt’s constraints.
2) Strong, consistent entity signals
To reliably recommend you, the system needs to be confident about your identity.
High-leverage fixes often include:
- One clear primary domain, with consistent canonical tags
- A single, consistent brand name format across profiles
- Consistent NAP data for local businesses (name, address, phone)
- Clean internal linking that connects your “About,” “Contact,” “Locations,” and core product pages
3) “Extractable” proof (not just marketing)
AI systems work well with content that can be turned into grounded statements:
- Specifications, policies, guarantees, and eligibility criteria
- Step-by-step instructions
- Pricing structure explanations
- Comparisons with clear definitions
- FAQs that reflect real user questions
This is one reason that AI-ready FAQs and metadata have become a practical GEO/AEO tactic: they turn implicit brand knowledge into explicit, reusable chunks.
4) Third-party corroboration
Many AI search experiences implicitly behave like a consensus engine. If multiple reputable sources describe your brand similarly, your recommendability increases.
This is not only about backlinks. It is about consistent descriptions, citations, and brand mentions in places the system can retrieve and trust.
5) Freshness and operational reality
For “best X right now” queries, recency matters.
If your content is outdated, or your location pages show old hours and old offerings, the model may prefer a competitor with more current signals. In some AI products, retrieval favors newer pages for time-sensitive intents.
Why your brand is not getting recommended (common failure modes)
Most visibility problems fall into a few patterns:
You are missing from the sources the system uses
If the assistant retrieves from sources that do not include you (or includes you only in thin, low-quality pages), you may not be in the candidate set.
The system cannot confidently resolve your entity
If your brand name, domain, and business details are inconsistent, the assistant may avoid recommending you to prevent mistakes.
Your key facts are not explicit
If the answer depends on facts that are only implied (or only present in images, PDFs, or JavaScript-heavy pages), the model may not extract them.
Your reputation footprint is lopsided
If the web contains mixed or negative sentiment about your brand with no clear, authoritative counterweight (policies, case studies, support pages, credible coverage), the model may hedge by recommending competitors.
Your pages are technically hard to process
If important pages are blocked, poorly canonicalized, or lack basic structured information, they may be under-retrieved, misinterpreted, or ignored.
What you can do to influence AI brand recommendations
You cannot “optimize” a single ranking algorithm anymore. You are optimizing an evidence graph.
Publish a brand entity hub (and make it easy to cite)
A strong hub page helps both humans and machines.
It should include:
- What you do, in one sentence, using the same category language customers use
- Clear product or service definitions
- Who it is for (and who it is not for)
- Proof elements (certifications, case studies, customer stories, guarantees)
- Links to official profiles and documentation
Add structured data that reduces ambiguity
Structured data does not guarantee recommendations, but it reduces confusion and makes extraction easier.
Relevant schemas often include Organization, LocalBusiness, Product, and FAQPage. Start with the shared vocabulary at Schema.org and validate implementation using Google’s documentation on structured data.
Create AI-ready FAQs that match real prompts
The fastest way to improve “prompt coverage” is to publish answers to the questions people actually ask assistants.
Examples:
- “What is the best option for [use case] in [location]?”
- “Which [category] supports [integration]?”
- “Is [brand] good for [audience]?”
Write these answers in a way that is factual, specific, and easy to quote.
Strengthen third-party coverage where it matters
Focus on sources that:
- Rank and get cited in your category
- Are recognized as authoritative by your customers
- Provide factual descriptions, not just promotional blurbs
This can include industry directories, review platforms, local listings, trade publications, and partner ecosystems.
Fix multi-location confusion
If you operate in multiple cities or regions, create a consistent location pattern:
- A dedicated page per location, with unique details
- Consistent naming and address formatting
- Clear relationships between brand, locations, and services
This reduces the risk that the model recommends the wrong branch, or avoids recommending you at all.
A practical cheat sheet: what an AI model can infer vs what you must make explicit
| Recommendation component | What the system is trying to do | What typically helps most | Common mistake |
|---|---|---|---|
| Intent match | Identify the user’s real goal and constraints | Clear positioning statements, “best for” pages, explicit use cases | Generic copy that fits everyone and therefore fits no one |
| Candidate set | Decide which brands to even consider | Consistent mentions in retrievable sources, solid entity pages | Being “popular on social” but absent from indexable, citable pages |
| Entity confidence | Ensure the brand identity is unambiguous | Consistent NAP, canonical domain strategy, structured data | Multiple domains, mismatched addresses, unclear parent-child brands |
| Evidence strength | Support claims with sources | FAQs, specs, policies, documentation, third-party coverage | Hidden facts (PDF-only), vague claims, no supporting pages |
| Safety and risk | Avoid harmful or unverifiable recommendations | Verifiable claims, clear disclaimers, transparent policies | Overpromising, medical or financial claims without support |
Where CapstonAI fits (turning “AI recommendations” into something you can manage)
Most teams struggle because they treat AI recommendations as random. The fix is to measure them like a channel.
CapstonAI is built to help brands and agencies track how major AI engines mention your brand, map prompts and mentions, identify blind spots, and publish AI-ready metadata and FAQs. That shifts AI visibility from guesswork to an operational loop: scan, diagnose, fix, and monitor.
If you want a starting point, begin with the CapstonAI free AI visibility audit to see how your brand is currently being described across AI search experiences.
Frequently Asked Questions
Do AI models recommend brands based on ads or paid placements? Most AI assistants are not simply ad-driven ranking systems in the way classic search ads work, but they may be embedded in products that include sponsored elements elsewhere. The recommendation text typically follows evidence, relevance, and policy constraints.
Why does my brand appear in one AI engine but not another? Different products use different retrieval sources, different safety policies, and different approaches to citations and grounding. If your visibility depends on a specific publisher or directory, you can see major variance across engines.
Is being #1 on Google enough to get recommended by AI assistants? It helps, but it is not sufficient. AI answers often depend on extractable facts, entity clarity, and corroboration across multiple sources, not just a single ranking position.
What is the fastest way to improve AI recommendations for my brand? Usually, it is (1) fixing entity confusion (domain, NAP, location pages), (2) publishing AI-ready FAQs that match common prompts, and (3) improving the quality and consistency of third-party coverage.
How can I tell which prompts lead to recommendations for my competitors? You need prompt and mention mapping, essentially tracking which user intents produce competitor citations and how often. That is the foundation for closing your “prompt coverage” gap.
Can structured data force an AI model to cite my site? No. Structured data improves clarity and extraction, but citation and recommendation are still driven by relevance, source selection, and trust.
Get a clear view of how AI engines talk about your brand
If AI search is already influencing how customers discover options in your category, you need to manage brand recommendations like you manage rankings and reviews.
Start with a free AI visibility audit from CapstonAI to see where you are mentioned (or missing), which prompts drive those mentions, and what to fix first to become the brand the AI model can confidently recommend.



