
When people search in 2026, they do not only “Google it.” They ask ChatGPT for a shortlist, they use Perplexity for sourced answers, they rely on Gemini inside Google products, and they increasingly get AI Overviews before they ever see ten blue links.
That shift changes what “best ai models” means for marketers.
If your goal is discovery (being mentioned, recommended, compared, and cited), the best AI models are not just the smartest on benchmarks. They are the ones:
- Your customers actually use in high-intent moments
- That pull from sources your brand can influence (your site, reputable third parties, product feeds, maps, review sites)
- That reliably mention brands with attributable, correct context
This guide breaks down the leading AI models people use for discovery in 2026, what they are good at, and how to prioritize them for an AI visibility strategy.
First, a practical definition: “model” vs “discovery surface”
Most buyers never interact with a raw foundation model. They interact with a surface (an app, a search experience, an assistant) that wraps the model with tools like web browsing, citations, shopping results, or enterprise knowledge connectors.
So instead of asking “Which model is best?”, teams should ask:
- Where does my audience discover vendors like us? (general research, product research, local search, B2B evaluation)
- Which AI surfaces influence that discovery? (ChatGPT, Google AI Overviews, Perplexity, Gemini, Claude)
- Which sources do those surfaces trust and retrieve from?
If you already have a GEO baseline, you will recognize this as the bridge between “LLM quality” and “GEO outcomes.” (If you need the foundation, see CapstonAI’s guide to Generative Engine Optimization (GEO).)
The best AI models for discovery in 2026 (and why)
Below are the main players most brands should care about for discovery. The “best” choice depends on your category and customer journey, but in practice, most teams end up prioritizing 4 core surfaces: ChatGPT, Google (Gemini plus AI Overviews), Perplexity, and Claude.
1) ChatGPT (OpenAI): best for conversational evaluation and shortlist creation
Why it drives discovery: ChatGPT is often used as a “decision companion.” People ask for recommendations, comparisons, alternatives, and step-by-step buying guidance. Those prompts naturally produce brand mentions.
Where it shines for brands:
- Competitive comparisons (“X vs Y”)
- Vendor shortlists by use case or budget
- Category education that shapes later purchase criteria
What typically determines whether you show up:
- Clear entity signals about your brand (consistent name, category, offerings)
- Strong web documentation and FAQs that are easy to summarize
- Third-party corroboration (reputable mentions, reviews, references)
Official reference: ChatGPT by OpenAI
2) Google Gemini (and Google’s AI surfaces): best for mass-market discovery
Why it drives discovery: In 2026, Google remains the default discovery layer for many journeys, and Gemini-powered experiences increasingly influence what users see and trust. Even when users do not “choose an AI tool,” they may still consume AI-generated summaries.
Where it shines for brands:
- Broad, high-volume informational discovery
- Local and “near me” intent when paired with business data consistency
- Queries that blend text with context from the broader Google ecosystem
What typically determines whether you show up:
- Excellent technical accessibility (crawlable pages, fast performance, clean canonicals)
- Strong structured data and on-page clarity (so content is extractable)
- Brand consistency across the web (citations, profiles, knowledge sources)
Official reference: Google Gemini
3) Google AI Overviews: best for “zero-click” brand impressions (and citation wars)
AI Overviews are not a standalone model, but they are a discovery surface that brands must treat as a top priority because they can compress the funnel.
Why they drive discovery: They can answer the query immediately and shape the narrative before users click. That means:
- If you are cited, you gain high-trust exposure.
- If you are not cited, your clicks can drop even if rankings hold.
If your growth strategy depends on organic, do not treat AI Overviews as a curiosity. Treat them as a competing SERP.
CapstonAI has a dedicated implementation guide here: How to Optimize for AI Overviews (2026).
4) Perplexity: best for sourced answers and research-style buying
Why it drives discovery: Perplexity’s user expectation is “show me sources.” For many categories, that makes it one of the most measurable AI discovery surfaces because you can track when you are cited (and where the citations come from).
Where it shines for brands:
- Research-heavy categories (B2B software, finance, healthcare info, technical products)
- “Best tools” queries where users want evidence
- Early-mid funnel queries that later become purchase decisions
What typically determines whether you show up:
- High-quality pages that answer specific questions directly
- Strong topical authority and reputable third-party coverage
- Data-dense content that is easy to cite (tables, definitions, comparisons)
Official reference: Perplexity
5) Claude (Anthropic): best for careful synthesis and enterprise knowledge workflows
Why it drives discovery: Claude is widely used for long-form synthesis, internal research, and drafting. In many organizations, it influences what teams recommend internally, which vendors they shortlist, and how they justify choices.
Where it shines for brands:
- Complex B2B evaluation and policy-heavy categories
- Summarizing long documentation, security pages, and technical guides
- Turning multiple sources into an internal decision memo
What typically determines whether you show up:
- Credible documentation (security, compliance, pricing pages if public, product docs)
- Clear positioning language that reduces ambiguity
- Consistent entity and product naming across pages
Official reference: Claude by Anthropic
6) “Other models” that matter, depending on your audience
You may also care about:
- Meta’s Llama ecosystem when your audience uses open-source tooling or when downstream apps embed it.
- Mistral and other open models in European enterprise stacks or developer-first workflows.
- xAI’s Grok if your category is heavily influenced by creator and social discourse.
These can matter a lot in niches, but for most brands, they are second-wave priorities unless you have clear evidence your buyers use them.
Quick comparison: which AI models most often drive discovery outcomes?
This table is intentionally decision-oriented (discovery), not benchmark-oriented (reasoning scores). Use it to set priorities for monitoring and optimization.
| AI surface (2026) | Best for discovery when… | Typical “win condition” for brands | What to watch | Priority for most teams |
|---|---|---|---|---|
| ChatGPT | Users ask for recommendations, alternatives, and buying guidance | Being recommended in shortlists and comparisons with correct positioning | Missing mentions on high-intent prompts, wrong category placement | High |
| Google Gemini experiences | Your audience is mainstream and discovery starts in Google | Being surfaced in AI-driven experiences tied to Google’s ecosystem | Entity confusion, outdated brand facts, inconsistent business info | High |
| Google AI Overviews | You depend on organic visibility for high-volume queries | Being cited (or at least accurately summarized) in AI Overviews | Citation loss, CTR drops, competitors taking overview citations | High |
| Perplexity | Buyers want sources and evidence | Earning citations from authoritative pages you control or influence | Which sources Perplexity chooses, citation quality and recency | High |
| Claude | Buyers do deep synthesis or internal evaluation | Being included in “research memos” and technical summaries | Incorrect claims about your product, weak documentation signals | Medium to High |
How to choose the “best AI models” for your brand (a 10-minute prioritization)
Instead of betting on hype, prioritize with a simple scoring approach.
Step 1: Map your discovery moments
Pick 5 to 10 prompts your buyers actually use. For example:
- “Best [category] for [use case]”
- “Alternatives to [competitor]”
- “Is [brand] good for [industry]?”
- “What should I look for when buying [product]?”
Step 2: Test across the big four
Run those prompts in:
- ChatGPT
- Google (watch both classic results and AI Overviews where they appear)
- Perplexity
- Claude
You are looking for patterns:
- Do you appear at all?
- Are you described correctly?
- Are competitors consistently included when you are not?
- Which pages and sources are being cited?
Step 3: Decide based on “surface fit,” not preference
A common mistake is to pick one model to optimize for. In discovery, your audience picks for you.
A better rule:
- If you are B2C or local, Google AI surfaces tend to be non-negotiable.
- If you sell B2B and buyers compare tools, ChatGPT and Perplexity usually dominate prompt-driven discovery.
- If your sales motion is enterprise, Claude often matters more than people expect.
What actually makes an AI model mention your brand?
Even though each surface behaves differently, the strongest cross-model drivers are consistent.
1) Entity clarity beats “more content”
If your brand is hard to classify, AI systems hedge or omit you.
Audit for:
- Inconsistent naming (brand vs product vs legal entity)
- Vague category language (“platform”, “solution”) without specifics
- Missing “about” context that ties you to clear use cases
2) Extractable answers beat long introductions
For discovery prompts, models tend to reuse content that is easy to lift into an answer.
Improve:
- Direct definitions and “who this is for” paragraphs near the top
- Short comparison sections with clear tradeoffs
- FAQ blocks that mirror user questions
3) Third-party corroboration often decides the shortlist
Many AI recommendations converge on what the broader web supports. That includes:
- Reputable reviews and roundups
- Credible publications
- Community discussion (category-dependent)
This does not mean “buy links.” It means building a presence that is consistent and verifiable.
4) Freshness and accuracy are now brand safety issues
If AI answers cite outdated pricing, old features, wrong locations, or past positioning, you lose trust at the moment of discovery.
That is why the discovery question is not only “Which models mention me?” but also “What are they saying, and how often does it change?”
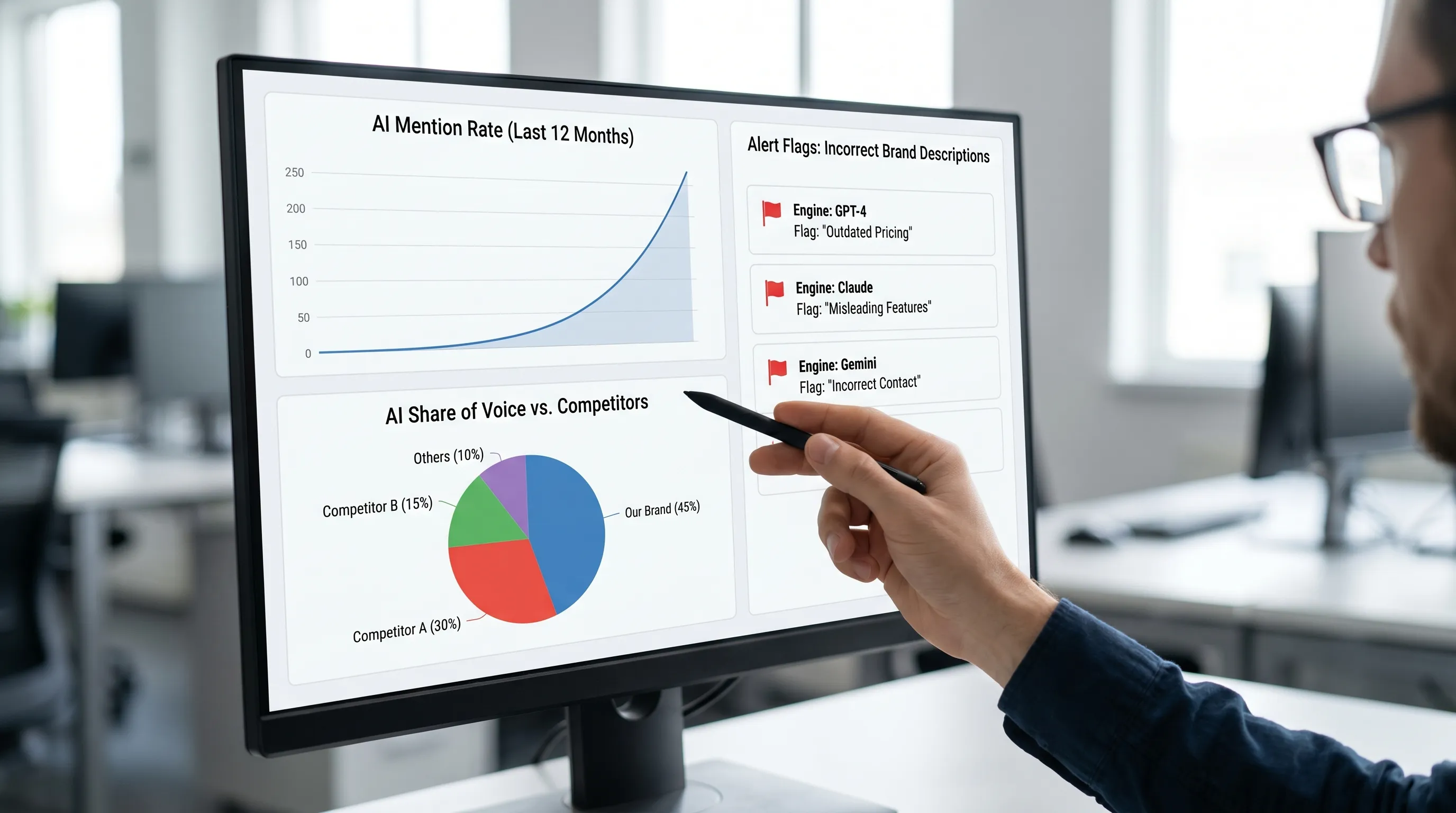
A practical 2026 playbook: turn AI discovery into a measurable channel
Most teams fail at AI discovery because they treat it like traditional SEO rank tracking. It is different. You need monitoring, diagnosis, and fast fixes.
Build your AI visibility workflow around four outputs
1) Prompt and intent coverage: Which high-intent prompts matter, and where do you appear?
2) Mention quality: When you are mentioned, is it accurate (category, features, locations, differentiators)?
3) Source mapping: Which URLs and third-party sources are feeding the answers?
4) Activation: What exact page changes (FAQs, metadata, schema, copy) will improve mentions and citations?
CapstonAI is built around this workflow. It helps brands, retailers, and agencies scan AI visibility across major AI engines, map prompts and mentions, track competitors, publish AI-ready FAQs and metadata, and push fixes via CMS integrations. If you want a starting point, begin with the free AI visibility audit.
For teams evaluating platforms, CapstonAI also maintains a buyer-focused comparison of GEO tooling: Best AI SEO Tools in 2026: 10 Platforms Compared.
Frequently Asked Questions
Which is the best AI model in 2026 for marketing discovery? The “best” depends on where your buyers search. For most categories, ChatGPT, Google’s AI surfaces (Gemini and AI Overviews), Perplexity, and Claude are the top discovery drivers.
Is Perplexity better than ChatGPT for discovery? Perplexity is often better when users want sources and citations, while ChatGPT is often stronger for conversational shortlists and guided comparisons. Many brands need both.
Do I need to optimize for every AI model? No. Start with the surfaces your audience uses, then expand based on measured mention gaps. A practical default is the big four (ChatGPT, Google AI surfaces, Perplexity, Claude).
How do I measure whether AI models mention my brand? You can manually test a prompt set across engines, but it does not scale. The scalable approach is automated scans that track mentions, prompt coverage, citations, and share of voice over time.
Why do AI models recommend competitors but not my brand? Common causes include weak entity clarity (models cannot classify you), lack of extractable answers (no direct definitions or FAQs), and insufficient third-party corroboration (few reputable sources mentioning you).
Get a clear answer to the real question: which models drive discovery for your brand?
“Best ai models” is only useful if you can connect it to your pipeline. The fastest way to do that is to audit where you show up today, identify the prompts you are missing, and deploy AI-ready fixes that improve mentions and citations across engines.
Start with CapstonAI’s free AI visibility audit to see how ChatGPT, Gemini, Claude, and Perplexity currently describe your brand, and what to fix first.



